AI 智能工具助手实战
核心结论
这不是一个 Demo 级别的玩具——6 层 Advisor 责任链、Token 级流式 SSE、LLM 重排序、智能切分、费用实时估算、人工审批队列,把前 26 章的所有知识点拼成一个可运行的生产级 AI 应用。一个项目覆盖 12 个章节核心知识点,写进简历就是完整的 AI 全栈项目经验,面试官问任何一个点你都能从源码级别回答。
- 🔥 全书总装现场,12 个章节核心知识点一个项目全串起来,学完直接起飞
- 💰 6 层 Advisor 责任链,业务代码零侵入,面试直接讲透 Spring AI 源码架构
- 🎯 Token 级流式 SSE,200ms 内看到第一个字,不是节点级流式,体验碾压同类项目
- 🚀 LLM 重排序 + 智能切分 + 费用估算 + 人工审批,生产环境真正需要的硬核能力
- 🧠 Graph 工作流 + 条件路由 + 质量检查 + 循环重试,完整展示 AI 应用的工程化落地
项目架构
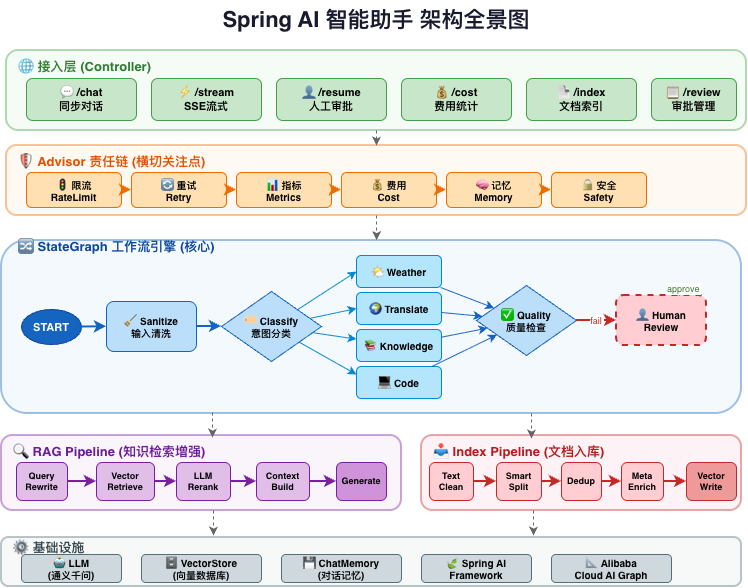
完整处理链路
用户输入 → 安全清洗 → 意图分类 → 条件路由 → 工具执行 → 质量检查 → 人工审批(可选) → 输出
- 安全清洗:Prompt 注入检测,恶意输入第一时间拦截,不给攻击者任何机会
- 意图分类:LLM 智能识别用户意图,精准路由到天气 / 翻译 / 知识问答 / 代码生成
- 质量检查:结构化输出评估回答质量,不合格自动触发人工审批
- 人工审批:approve 直接输出,reject 回到意图分类重新处理,形成完整闭环
八大核心亮点,个个都是面试杀器
亮点一:6 层 Advisor 责任链——业务代码零侵入
这是本项目最核心的设计,所有 LLM 调用自动经过 6 层横切处理,执行模型类似 Servlet Filter,但拦截的是 AI 调用而不是 HTTP 请求:
| 层级 | Advisor | Order | 职责 |
|---|---|---|---|
| 最外层 | RateLimitAdvisor | -100 | 令牌桶限流,保护 API 配额,超时直接拒绝 |
| 第二层 | RetryAdvisor | -50 | 指数退避重试(1s→2s→4s),超时/限流才重试,参数错误不重试 |
| 第三层 | MetricsAdvisor | 0 | 指标采集,每次调用的耗时、Token 数全部记录 |
| 第四层 | CostCalculatorAdvisor | 10 | 费用实时估算,微元精度,单次超阈值自动告警 |
| 第五层 | ChatMemoryAdvisor | 50 | 对话记忆持久化,让 AI 记住你是谁、聊过什么 |
| 最内层 | SafetyAdvisor | 100 | 安全兜底,最后一道防线 |
"Spring AI Advisor 链的执行模型是什么?" "和 Servlet Filter 有什么区别?" "ChatModelCallAdvisor 是什么时候加进去的?" 本项目从源码级别讲透 DefaultAroundAdvisorChain 的调度机制,面试直接秒杀。
亮点二:Token 级流式 SSE——200ms 看到第一个字
不是等 AI 全部生成完再返回,也不是节点级流式,而是真正的 Token 级流式——用户 200ms 内就能看到第一个字,体验完全不同:
progress事件:实时展示处理阶段(安全检查 → 意图分类 → ...)token事件:逐字推送 AI 回答,打字机效果quality事件:质量检查结果实时反馈done事件:处理完成,前端关闭连接
亮点三:RAG Pipeline 责任链——LLM 重排序是灵魂
RAG 不再是单节点调用,而是拆成 4 步 Pipeline,每步只做一件事:
LLM 重排序是核心中的核心——向量相似度 ≠ 语义相关性。Embedding 模型的语义理解有限,可能把"表面相似但实际不相关"的文档排在前面。LLM 的语义理解远强于 Embedding,能更准确判断"这条文档是否真的回答了用户的问题"。这一步直接决定了 RAG 的回答质量。
亮点四:智能切分——不在句子中间截断
- 第一阶段:按段落(双换行)预切分,保持语义完整性
- 第二阶段:超长段落按 maxChunkSize 二次切分,带 overlap 保持上下文连贯
- 尝试在句号/问号/感叹号处断开,绝不在句子中间粗暴截断
亮点五:费用实时估算——微元精度,告别浮点陷阱
- 原子计数器
AtomicLong累计费用,并发安全 - 微元存储(1 元 = 1000000 微元),彻底避免浮点精度问题
- 单次费用超阈值自动告警,钱花到哪里一目了然
亮点六:质量检查结构化输出
LLM 直接返回 Java 对象 QualityEvaluation(pass, reason),不合格时自动进入人工审批队列,approve 输出、reject 回到意图分类重新处理,形成完整的质量闭环。
亮点七:双 ChatClient 模式——内部处理和用户交互彻底隔离
baseChatClient:不带 Advisor,用于意图分类、质量检查等内部处理(不需要记忆,不应该混入用户对话历史)advisedChatClient:带完整 6 层 Advisor 链,用于天气查询、翻译、代码生成、知识问答等用户交互节点
亮点八:真实天气 API + 降级
Function Calling 调用 wttr.in 免费天气 API(无需 API Key),异常时自动降级为模拟数据,保证服务永远可用。
知识点覆盖清单
| 章节 | 在本项目中的体现 |
|---|---|
| 第 2 章 Spring AI 基础 | ChatClient 构建与调用 |
| 第 4 章 Prompt 工程 | 各节点的 system prompt 精心设计 |
| 第 5 章 结构化输出 | QualityEvaluation record 直接反序列化 |
| 第 6 章 Embedding | RAG Pipeline 中的向量检索 |
| 第 7 章 向量数据库 | VectorStore.similaritySearch |
| 第 9 章 RAG | 4 步 Pipeline:改写→检索→LLM重排→组装 |
| 第 13 章 Function Calling | 天气节点的 @Tool 注解 + 真实 API |
| 第 17 章 Graph 工作流 | StateGraph 全部 API + 条件路由 + 循环 |
| 第 20 章 对话记忆 | MessageChatMemoryAdvisor 持久化 |
| 第 23 章 安全防护 | SanitizeNode 输入清洗 + SafetyAdvisor 兜底 |
| 第 24 章 可观测性 | MetricsAdvisor + CostCalculatorAdvisor |
| 第 25 章 性能优化 | Token 级流式 SSE 输出 |
一个项目覆盖 12 个章节核心知识点,写进简历就是完整的 AI 全栈项目经验。面试官问 Advisor 链、问 RAG、问 Graph 工作流、问流式输出、问安全防护——你都能从源码级别回答,这就是核心竞争力。